ベロシティの安定化
今回はアジャイル開発における「ベロシティの安定化」について、僕の考えをまとめようと思います。 アジャイル開発をしていて、バーンダウン上に現れるベロシティーが安定せず、計画通りにうまくいってるかわからない、リリースの着地予定がわかりづらいと思ったことはないでしょうか?僕はこのあたりに悩んだことがなん度もあり、なんとかしたいなぁと思っていました。そこで色々な書籍を読んだり、自分で実践してみて効果があったものについてまとめようと思います。
ベロシティとは?
まずベロシティとは何かについて軽く説明します。色々な定義があると思いますが、ここでは対象となるチームにおいて、1イテレーションあたりで消化できるストーリーポイントの合計とします。
なぜベロシティを安定させたいか
冒頭でも触れましたが、そもそもなぜベロシティを安定させたいかについて僕なりの考えを説明します。すばり理由は「より正確にリリースのタイミングを予測」ためです。リリースのタイミングが予定より、遅れているか、早いかを知ることで、色々なステークホルダーに対するコミュニケーションの仕方を変えることができます。予定より遅れそうなのでリソースを増やしてほしいであったり、リリースが早くなりそうだからPRを打つタイミングを早めた方がいいなどの経営的な意思決定を支えることができます。 ではベロシティが安定していないとどうなるかといいますと、いつリリースされるかの予測がとてもしづらい状況になってしまします。例えば、1イテレーション目が2pt、2イテレーション目が10pt、3イテレーション目が4ptだとします。平均をとってこのチームのベロシティを(2+10+3)/3=5ptとすると、リリースまでに40ptのとき、40pt/5pt=8イテレーションで開発が終わると予測することができます。ただ正直2pt、10pt、3ptもぐらぐらしたバーンダウンを見て、本当に8イテレーションで終わると自信をもって自分たちが言えるか、他の人が納得できるか結構微妙だと思っています。たまたまその3つの平均をとったときのベロシティが5ptなだけでは?と捉えられてしまいます。一方これが例えば、1イテレーション目が4pt、2イテレーション目が6pt、3イテレーション目が5ptだとします。このときベロシティが5ptと説明されると割と皆さん納得できるのではないでしょうか?開発チーム側も自信を持ってリリースの予測を伝えることができます。
どうやって安定させるか
ではどうやってベロシティを安定させるのでしょうか?いくつか効果がありそうなものを3つご紹介します。
リリースに拘る
1つ目がリリースに拘るです。ポイントはDoneにならないと計上されないので、いかにリリースに拘るかが重要です。CI/CDパイプラインは常に整備しておく出会ったり、B/Gデプロイメント、フィーチャートグルなどを活用して、安全、安心にリリースできる仕組みを整えることが重要です。(ここでいうリリースはお客様に公開するだけでなく、内部的なリリースも含めてリリースと呼んでいます)
ストーリーを細かく分割する
2つ目がストーリーを細かく分割するです。極端な例で言うと、1週間では終わらないストーリーがあると、その1週間は0ptになってしまい、次のイテレーションに大きく計上されることになってしまいます。ストーリーが細かいとイテレーションのはじめでもDoneとなるストーリーの数が以前より増えると思います。それに後述するリファクタリングのレベルの調整がしやすくなります。
リファクタリングのレベルを調整する
3つ目がリファクタリングのレベルを調整するです。 順調に進んでいる時に大きめのリファクタリングをし、消化が悪い時は少なうことで、ベロシティを平準化させることができいます。例えば、普段ベロシティ8ptぐらいのチームで、現在、イテレーションの半分で6pt消化できているとなれば、余裕があると認識ができ、もう少し気になるところをリファクタリングしようといった行動がとりやすくなっていきます。このリファクタリングによって未来のベロシティを向上させることができるので、とてもいい効果があると思います。
1イテレーションの長さを長くする
4つ目は1イテレーションの長さを長くするです。ここはメリデメがあり個人的にはそこまでおすすめはしません。基本的にイテレーションが短いほどベロシティは不安定になります。終わり切らないストーリーが発生しやすくなったり、思ったより重いストーリーが重なってしまったりするからです。一方イテレーションが長いと、変化への対応が遅くなると言うデメリットがうまれます。ここはバランスが大事なところです。僕のおすすめは1週間のイテレーションにして、ストーリーの分割でベロシティを安定化させる方がいいかなと思っております。
まとめ
以上僕が考えるベロシティの安定化をさせたい理由とその方法でした。一方でベロシティを制御しにいくものではないと言う考えもあるとは思います。しかし、僕個人としては一定意識してコントロールすることのメリットは大きいとお思い上記の考えを述べさせていただきました。 以上お読みいただきありがとうございます。
アジャイルな計画と実践
2年ほどアジャイル開発(XP)を行なって来た上での学びを一度整理しようと思います。
主に観点は以下の3つです。
- ストーリーの分割粒度について
- 計画時のコツ
- クォーターにリリースするフィーチャー決め、リリースプランニング、イテレーションプランニング
- ベロシティを安定化させる方法
前提として僕が所属する組織は、大まかに対象クォーターでリリースしたいフィーチャー決め→リリースプランニング(プランニングゲーム)→イテレーションプランニングの順に計画を行っています。
またストーリーとフィーチャーを厳密に使い分けて書いてないです。(ストーリーの塊や大きめのストーリーをフィーチャーと捉えています)
ストーリーの分割粒度について
ストーリーの分割粒度は、タイミングによって異なります。僕が所属する組織では主に3段階の計画が存在します。
- 大まかに一定の期間のうちにリリースしたいフィーチャーのを決めたいとき→大
- 機能の中でもさらに粒度細かくストーリーを出し、プランニングゲームをしてバーンダウンチャートを作成したいとき(リリース計画)→小
- 該当ストーリーを実際に着手するイテレーションのプランニングのタイミング〜実際に実装するタイミング(イテレーション計画)→極小
そしてそれぞれ、1が大、2が小、3が極小の粒度でストーリーを出します。以下例です。
フィーチャー決め:大
- 例. ユーザーは企業情報ページを見れる
- ページ単位とか、その中の数個の機能ぐらい粒度
リリースプランニング:小
- 例. ユーザーは企業情報ページで企業名を見れる
- ここではINVESTをできるだけ保つ
イテレーションプランニング:極小
- 例. ユーザーは企業情報ページで企業名欄を見れる・ユーザーは企業情報ページで企業名を見れる
- 長くても1日でリリースできるぐらいの大きさで、理想は1時間程度でリリース可能な大きさ
なぜこのように分割流動が違うかというと、それぞれでストーリーに求める目的が違うからです。
フィーチャー決め時の目的
- 主に経営に関わる意思決定に主に使われる。事業計画とかリソース配分とか
リリース計画の目的
MVP、対象期間(1四半期とか)のスコープを定める
大体いつどの機能が出るのかを把握する
マーケティングとか、お客さんと接するビジネスサイドのコミュケーションに使える
開発チーム内での仕様の認識の確認
開発とPDMで仕様の認識の確認
イテレーション計画の目的
- 頻繁にリリースを行う為のストーリーの分割
- より詳細に仕様、実装イメージをすり合わせる
実際着手してわかったことの反映
- ここは場合分けがあるので、ストーリーも分割しましょうとか
補足なのでうがストーリーの粒度がなぜ、「大中小」ではなく「大小極小」にしたかというと、僕の中での規模の感覚が「大小極小」だからです。2のタイミングで一定細かい方が仕様の漏れがなくなり、後々計画と実際のズレが少なくなります。
計画時のコツにやることとコツ
フィーチャー決め
やること
ざっくりクォーターで何ポイントぐらい消化できそうか
- クォーターで大体どんぐいらいポイント増加するかも考慮しといた方がいい
大きな単位の機能の見積りをする
実現可能性の調査
- 技術的、法的、既存で所持している資産 (リリース済みが) etc…
コツ
- 仕様を細かく把握しようとしすぎない
- 見積もりの粒度は3段階ぐらいでいい
- 今まで出してきた機能からの大体の相対値で決める
- このページは合計何ポイントぐらいだからこのページも何ポイントぐらいみたいな
イテレーションプランニング
やること
- 細かい単位のストーリーを出し、見積もり
- 予測消化を求める
- プランニングゲームをする
- バーンダウンチャートを引く
- 細かい単位のストーリーを出し、見積もり
コツ
思ったより細かく出す
- 参考: https://www.slideshare.net/kentjmcdonald/21-story-splitting-patterns-49940134
- PdMがわかりづらくなりすぎないことに注意する
見積もりは相対見積もりがコスパがいい(精度と早さ)
できるだけINVESTを保つ
- 例えばストーリー間に依存があるとプランニングゲーム時にストーリーの入れ替えがしづらくなるから
- ただし一方独立性は、場合によっては破ってもOKだとも思おう。その方が使用の漏れがなくなる、見積もり的にあきらかに不自然になる場合。(基盤部分を作るストーリーと、それぞれの対応みたいなもの。ユーザーはVISAカードで支払いができる、Masterカードで支払いができるをそれぞれ独立したもの前提でポイントをふることに違和感があるときはユーザーはクレジットカードで支払いができるという基盤のストーリーを作るとか)
予測増加を盛り込む
- 過去の実績を参考にする
- アートオブアジャイルデベロップメント2いわく、安定したチームにおいて、40%バーファーを設けると50%の確率で全てのストーリーが終わると書かれている
- 過去の実績を参考にする
既存の実装はない前提でポイントをふる
- ポイントにはテスト、実装、リファクタの分の大きさが含まれる。テストを書く必要があったり、リファクタの対象になる可能性があるなら、既存の実装があってもない基本ない前提で振るべき。結果開発が早くなるときはあるがベロシティが上がるだけでポイントが変わるわけではない。実体験として基本そうした方がうまくいく。
対象のコンテキスにおける予測消化を考える
- 関わるドメイン、技術が変わると同じチームでも全然違ったベロシティとなる。
- 過去似たような状況のプロジェクトでどうだったかを自分達で振り返ったり、周りに聞いたりする
- 次の期間でそのチームが触るコンテキストが異なる場合はできれば1つストーリーをやってみる。無理なら過去そのようにコンテキストがスイッチしたタイミングでどのぐらいのベロシティになったかを参考にする
- 関わるドメイン、技術が変わると同じチームでも全然違ったベロシティとなる。
イテレーションプランニング
やること
- 今週やるべきストーリーのコミットメントを決める
- ストーリーを分割する
- 場合によってはストーリーの実現方法を詳しく共有する(僕の組織ではあえて細かくやってなかったりする)
コツ
今までストーリーをやってみて、これからやるストーリーに反映させるべき点はないかを考える
ストーリーの分割
TDDのプロセスと同じ感覚で分割する。 参考: https://www.slideshare.net/kentjmcdonald/21-story-splitting-patterns-49940134
固定文字をまずは出す
- 空のページを出す
- ループの場合は0->1->ループに分解
ユーザーがやる処理を徐々に自動化しようという目線を持つ
このタイミングではストーリー間での独立性がなくても問題にならないことが多いので、そこまで気にしない。ただしVertical Sliceは意識する。そこを無視して分割すると、どっかにボトルネックが発生する可能性がでてきてしまう
ベロシティの安定化のコツ
ほぼ計画でベロシティが安定するかは決まってしまう一面がある一方で、実際に行う上でのコツもある。
一番大事なのはストーリーを滞留させず、頻繁にリリースすることである。
そのためには、1ストーリーでやることをシンプルにする(ストーリーのサイズを小さくする)ことが必要である。
そのためには以下のことに気を付ける。
- ストーリーでやるべきことをシンプルにする。TDDと同じ思考
- プロジェクトの作成だけ、テストのライブラリ入れるだけ、とかlinterを入れる、CICDを整えるとかを少しずつやっていく
- それぞれストーリーをわけてもいいぐらい
- これを通常のユーザストーリーの1つめに全部やろうすると時間がかかり滞留する
- イテレーションのコミットしたポイントが達成できそうかを日々考えて改善の量、コードの質の調整をする
- 1周目のストーリーは薄くやって、横展開モードの時にしっかり目にリファクタする
- ストーリーが小さいと上記の行動がとりやすくなる
- 頻繁にリリースできるようにする
- フィーチャートグルを使う。下位互換性を持ったコードを書く。(一部しかできていなからデグレするリリースになることを防げる)
頻繁にリリースすることはベロシティ安定以外にいも細かくFBが得られる、トランクベース開発をしている時、リモートとローカルの差分が小さくなるなどのメリットもある。
Microservice間におけるデータの一貫性について
今回は以前から読みたかった本であるMicroservices Patternsを読みましたので、この本の中から特に印象に残ったMicroservice間において擬似的にトランザクションを貼る方法であるSagaパターンについてお話させて頂きます。
Sagaパターン
Sagaパターンとは、localトランザクションの繋がりであるSagaを実行し、失敗時にはそれぞれの補償トランザクションを使って、前のSagaによって行われた変更を戻しデータの一貫性を保つ方法です。つまり、失敗したときは自力でロールバックするような機構を作っておきましょうってことです。Microservices 下記にこちらの本に載っているSagaの例を載せておきます。

これはUber的なサービスでオーダーが作成される場合のSagaの例です。 またこのアプリケーションのアーキテクチャは以下の通りです。
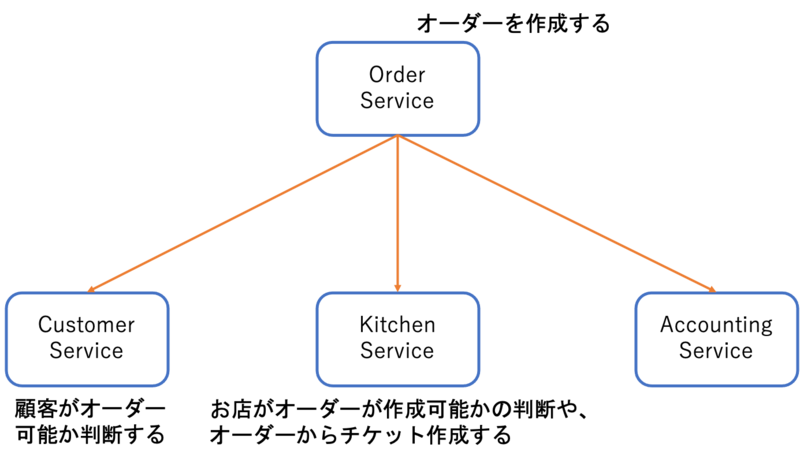
このアプリケーションにおけるトランザクションとそれに対する補償トランザクションは以下のようになります。
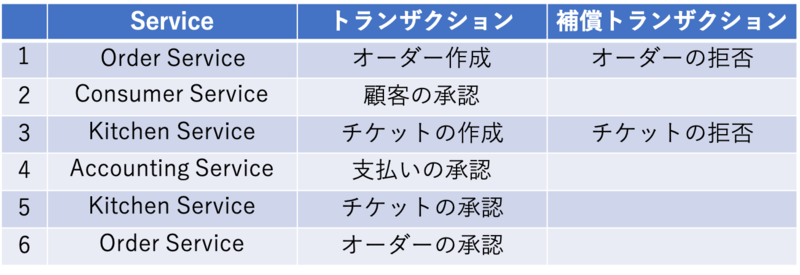
本書ではオーダー、チケットは作成したタイミングでは、オーダーの状態が、PENDINGになっており、承認されるとAPPROVEDになり、拒否されるとREJECTEDとすることで補償トランザクションの仕組みを実装していました。 こうやって自力でロールバックを実装することで擬似的にmicroservice間でトランザクションを貼ることができるようになります。 またこのSagaパターンは構成に2つのパターンがあるので、次はその2つのパターンについて解説していきます。
Choreographyパターン
Choreographyパターンは、自分が実行された後、次の実行へのトリガーを自分で実行するパターンのことを指します。今回の例における流れを以下に示します。

オーダー作成が成功するパターン
- Order ServiceはAPPROVAL_PENDING状態のOrderを作成し、OrderCreated eventを発行する
- Consumer ServiceはOrderCreated eventを受け取り、顧客がオーダー可能かを判定し、ConsumerVerified eventを作成する
- Kitchen ServiceはOrderCreated eventを受け取り、オーダーのバリデーションを行い、CREATE_PENDING状態のTicketを作成し、TicketCreated eventを作成する
- Accounting ServiceはOrderCreated eventを受け取り、PENDING状態のCreditCardAuthorizationを作成する
- Accounting ServiceはTicketCreated eventとConsumerVerified eventを受け取り、顧客のくクレジットカードに請求をして、CreditCardAuthorized eventを発行する
- Kitchen ServiceはCreditCard Authorized eventを受け取り、TicketをAWAITNG_ACCEPTANCE状態に変更する
- ORDER SERVICEはCreditCardAuthorized eventを受け取り、OrderをAPPROVEDに変更して。OrderApproved eventを発行する
クレジットカードの認証に失敗しオーダー作成が失敗するパターン
- Order ServiceはAPPROVAL_PENDING状態のorderを作成し、OrderCreated eventを発行する
- Consumer Serviceが、OrderCreated eventを受け取り、顧客がオーダー可能かを判定し、ConsumerVerified eventを作成する
- Kitchen ServiceはOrderCreated eventを受け取り、オーダーのバリデーションを行い、CREATE_PENDING状態のTicketを作成し、TicketCreated eventを作成する
- Accounting ServiceはOrderCreated eventを受け取り、PENDING状態のCreditCardAuthorizationを作成する
- Accounting ServiceはTicketCreated eventとConsumerVerified eventを受け取り、顧客のクレジットカードに請求をしたが失敗しCreditCardAuthorized Failed eventを発行する
- Kitchen ServiceはCreditCard Authorized eventを受け取り、TicketをREJECTED状態に変更する
- ORDER SERVICEはCreditCardAuthorized Failed eventを受け取り、OrderをREJECTEDに変更する 6と7でオーダーとチケットを拒否しているのが成功パターンと違う点です。
このパターンはわかりやすい反面、以下のような欠点があります。 - Sagaパターンの実装が各サービスに分散する - 相互依存になる - 密結合になるリスクがある
「 Sagaパターンの実装が各サービスに分散する」と言うのは、各サービスがSagaを意識した実装を行わなければならないと言う意味です。OrchestrationパターンはSagaを意識するのがOrchestratorのみで済みます。 「相互依存になる」と言うのは、補償トランザクションを実行している部分を見ると、Order ServiceもAccounting Serviceに依存しているし、Accounting ServiceもOrder Serviceいることがわかります。このようにChoreographyパターンは相互依存を生んでしまいます。 「密結合になるリスクがある」と言うのは、各サービスが自分が関連するサービス全てのイベントをサブスクライブしないといけず、サービス同士が密に結合してしまうと言うことです。 以上のような欠点があることから一般的には次のOrchestrationパターンが良く使われるすです。
Orchestrationパターン
こちらのパターンはSaga orchestratorを用意し、各サービスの調整をOrchestratorが行うパターンです。

Order Serviceの中にSaga orchestratorがいるような構成になっています。 オーダー作成が成功した場合以下のような流れになります。 1. Saga orchestratorがVerify Consumer commandをConsumer Serviceが送る 2. Consumer Serviceが Consumer Verifiedと返信する 3. Saga OrchestratorはCreate TicketコマンドKitchen Serviceに送る 4. Kitchen ServiceはTicket Createdと返信する 5. Saga OrchestratorはAccounting ServiceにAuthorize Cardメッセージを送る 6. Accounting ServiceはCard Authorizedメッセージを返信する 7. Saga orchestratorはApprove TicketコマンドをKitchen Serviceに送る 8. Saga OrchestratorはApprove OrderコマンドをOrder Serviceに送る
このパターンの場合、途中で作成が失敗した場合は、Saga orchestratorが補償トランザクション実行のためのイベントを発行します。つまりAccounting ServiceがOrder Serviceを叩くといったことがありません。 つまり、常にSaga orchestratorが各サービスを実行し、その逆がないのでこのパターンの特徴です。なので、Saga orchestratorにSagaに関する知識が集約され、また相互依存がなくなります。 以上2つのパターンについて解説しました。次にこのSagaパターンを実装するに当たっての大切な注意点について述べます。
注意
このSagaパターンを実装するに当たって注意として挙げられているのが、それぞれのlocalトランザクションと、次のServiceへのイベントの発行がアトミックに行わなければならないと言う点です。localトランザクションでDBへの変更ができていても、イベントの発行ができていなければ意味がありません。よってアプリケーション上でDBへの保存、次にイベントの発行というコードを書くことは望ましくありません。 上記を実現するための手段して挙げられているのが、Transaction Log Tailingです。これはDBのコミットログを追い、それらをMessage brokerへのイベントに変換して送信する方法です。こうすることでDBへの変更とイベントの発行がアトミックになります。これらをサポートするサービスとしてDebeziumなどがあるそうです。
感想
Sagaパターン正直難しかったです、、笑 Microservice間においてトランザクションてどうすんやろうと思ってたのですが、Sagaパターンにはある意味泥臭く頑張るという印象を受けました。導入の際は気を付けないとシステムの構成が複雑になってしまうのと感じました。なのでそこまで一貫性を保つことが必須でない場合は、リトライをそれぞれの処理に入れるとか、定期的にバッチ処理で同期させるようにするとか他のアイディアも検討した後に導入すべきだなぁと思いました。ただ個人的には面白そうなのでどっかで実装し見たいと思います! またこの本は他にもサービスメッシュや、E2Eテストの話、Api Gateway、BFFやCQRSなどについても載っているのでMicroserviceに興味のある方は是非お読みください!実際のコードもここに上がっています。
Cypress × Firebase × Angular の組み合わせのE2EをGitHub Actionsで実行する
前回はCypress × Firebase × Angularの組み合わせのアプリケーションのe2eをLocalで回す方法を説明しました。今回はで開発環境でe2eを実行し、通った場合に、staging環境にデプロイするGitHub Actionsのパイプラインを構築します。 またモノレポ想定でアプリケーションのsourceも、e2eのsourceも同じプロジェクト内にいる構成になっています。 今回のコードはここにおいています。
開発・staging 環境の準備
今回はfirebase hostingを使ってアプリケーションを公開します。環境の切り替えはfirebaseのプロジェクトを複数作ることで実現します。つまり開発環境用プロジェクト、staging環境用プロジェクトを作ってしまって、そこにアプリケーションをデプロイしe2eを回します。なのでプロジェクトを作成していない方はfirebaseのプロジェクトを作成し、firestoreとhostingを実行できるようにしておいてください。
Angularのアプリケーションなので、環境の切り替えはファイルで行うことになります。こちらのサイトを参考にしながらangular.jsonに設定を追加することで様々な環境設定ファイルを切り替えられるようになります。今回はdevとstagingを用意しています。
ファイルで環境を切り替えられるのですがfirebaseのシークレットの情報はrepositoryにpushすべきではないので、pipelinde実行するには少しトリッキーな方法を使う必要があります。このあたりは後ほど解説します。
パイプラインの流れ
大きな流れは以下のようになっています。

開発環境にデプロイ
まずは開発環境にデプロイする方法について解説します。開発環境にデプロイする用のymlは以下のようになります。
// $PROJECT_ROOT/.github/workflows/pipeline.yml
name: new-app-e2e-pipeline
on: [push]
jobs:
deploy-to-dev-for-e2e:
runs-on: ubuntu-20.04
steps:
- name: Checkout Repo
uses: actions/checkout@v2
- uses: actions/setup-node@v1
- run: npm install -g firebase-tools
- name: Decrypt secret
run: ./decrypt_secret.sh environment.dev.ts
working-directory: ./.github/scripts
env:
LARGE_SECRET_PASSPHRASE: ${{ secrets.LARGE_SECRET_PASSPHRASE }}
- name: Move secret
run: mv $HOME/secrets/environment.dev.ts ./new-app/src/environments
- name: Build and Deploy to dev
run: ./build_and_deploy.sh dev
shell: bash
working-directory: ./enviroments/firesbase
env:
FIREBASE_TOKEN: ${{ secrets.SERVICE_ACCOUNT }
はじめの部分ではpushがトリガーであることやfirebase-toolsのinstallをしています。
Decrypt secret、Move secret部分は少しややこしいので解説をします。Angularは基本的に環境変数を受け取れない (僕が知る限り) ので、環境ごとの設定の切り替えはファイルで行います。しかし、GitHub Actionsでは安全にファイルをアップロードする仕組みは特にありません。なのでenv ファイルを暗号化してpushを行い、パイプライン上で複合化する必要があります。
暗号化したいファイルはgpgおよびAES256暗号アルゴリズム使って以下のように行います。
gpg --symmetric --cipher-algo AES256 my_secret.json
この時聞かれるパスフレーズは覚えておいてください。
複合化は以下のdecrypt_secret.shを使っています。
// $PROJECT_ROOT/.github/scripts/decrypt_secret.sh
#!/bin/sh
FILE_NAME=$1
# Decrypt the file
mkdir $HOME/secrets
# --batch to prevent interactive command
# --yes to assume "yes" for questions
gpg --quiet --batch --yes --decrypt --passphrase="$LARGE_SECRET_PASSPHRASE" \
--output $HOME/secrets/$FILE_NAME "${FILE_NAME}.gpg"
$LARGE_SECRET_PASSPHRASEは暗号化する際に聞かれたフレーズを指します。これを予めGitHubのsecretsとして登録しておくことで、環境変数として取り出すことができます。登録方法や詳しい、このあたりの流れはこちらを参考にしてください。
Move secretは複合化されたenv fileをangularのenvironmentsディレクトリに移動させています。
ちなみにちょくちょく見受けられるworking-directory:~はコマンドが実行されるディレクトリ を指定します。
Build and Deploy to devでは予め作成したAngularのアプリをビルドして、firebaseのプロジェクトにデプロイしてくれるシェルを叩いています。
$PROJECT_ROOT/environments/firebaseでfirebase initを行い、firebaseの設定ファイル生成させてbuild、deployを行うシェルをおいています。その中では$PROJECT_ROOT/environments/new-appにあるbuild用のシェルを実行するようにしています。
deployを行うシェルではfirebase deployを実行しているのですが、その際にFIREBASE_TOKENという環境変数が必要となります。これはlocalでfirebase login:ciを叩き、ログインをすると返却されるトークンで、これをsecretとして登録する必要があります。(pipeline.ymlのFIREBASE_TOKEN: ${{ secrets.SERVICE_ACCOUNT }の部分)
またfirebase use --addで各環境にdev、stagingというaliasを貼っています。
aliasについては詳しくはこちらをご覧ください。
// $PROJECT_ROOT/environments/firebase/build_and_deploy.sh
## !/usr/bin/env bash
set -e
env=$1
env=${env:-"dev"}
src=sources
cwd=$(realpath $(dirname $0))
project_root=$(git rev-parse --show-toplevel)
cd ../tuning-front
./build.sh "${env}"
cd ${cwd}
echo "deploy to ${env}"
firebase deploy --project ${env}
rm -rf "${cwd}/public/"
// $PROJECT_ROOT/enviroments/new-app/build.sh
## !/usr/bin/env bash
set -e
env=$1
env=${env:-"dev"}
echo "build ${env} mode"
src=sources
cwd=$(realpath $(dirname $0))
project_root=$(git rev-parse --show-toplevel)
rm -rf "${cwd}/${src}"
echo "copy project.."
cp -R "${project_root}/new-app" "${cwd}/${src}"
cd "${cwd}/${src}"
rm -rf dist/
ls src/environments
echo "build project.."
npm install -g @angular/cli@11.0.1
npm install
ng build -c "${env}"
echo "copy output to firebase public.."
cp -R "${cwd}/${src}/dist/new-app/" "${project_root}/enviroments/firesbase/public"/
rm -rf "${cwd}/${src}"
e2eの実行
e2e実行用のymlは以下のようになります。
execute-e2e:
runs-on: ubuntu-20.04
needs: deploy-to-dev-for-e2e
steps:
- uses: actions/checkout@master
- name: Decrypt secret
run: ./decrypt_secret.sh serviceAccount.json
working-directory: ./.github/scripts
env:
LARGE_SECRET_PASSPHRASE: ${{ secrets.LARGE_SECRET_PASSPHRASE }}
- name: Move secret
run: mv $HOME/secrets/serviceAccount.json ./e2e
- name: Create videos and screenshots directory
working-directory: ./e2e/cypress
run: |
mkdir videos && \
mkdir screenshots
- name: Cypress Run
uses: cypress-io/github-action@v2
with:
working-directory: e2e
start: npm run cypress:run
wait-on: https://new-app-dev-edb1d.web.app
browser: chrome
record: true
env:
CYPRESS_RECORD_KEY: ${{ secrets.CYPRESS_RECORD_KEY }}
FIREBASE_TOKEN: ${{ secrets.SERVICE_ACCOUNT }}
GITHUB_HEAD_REF: ${{ github.head_ref }}
GITHUB_REF: ${{ github.ref }}
- uses: actions/upload-artifact@v1
if: failure()
with:
name: cypress-screenshots
path: e2e/cypress/screenshots
- uses: actions/upload-artifact@v1
if: failure()
with:
name: cypress-videos
path: e2e/cypress/videos
基本的にはcypresの公式を参考にしています。
needs: deploy-to-dev-for-e2eは前のジョブが終わってから行うという意味の記述です。これがないと並列で動いてしまいます。
Decrypt secret、Move secretでは予め暗号化した、serciceAccount.jsonを複合化し、所定のディレクトリに移動させています。このファイルはcypressがfirestoreなどを触るために必要な認証情報です。
Create videos and screenshots directoryではcypressがテスト時にscreenshotやvideoを記録するためのディレクトリ を作成しています。(公式では記述を見つけることができなかった、これがないとe2eがコケるので作成しました。)
Cypress Runではテストを実際に実行しています。 npm run cypress:runでテストが実行できるよう、e2eディレクトリのpackage.jsonに以下のように記述しています。
"cypress:run": "cross-env cypress run"
その後の部分はテストが失敗した際にvideosとscreenshotsをアップロードする設定をしています。
stagingへのデプロイ
以下がstaginへのリリース部分です。
deploy-to-staging:
runs-on: ubuntu-20.04
needs: execute-e2e
steps:
- name: Checkout Repo
uses: actions/checkout@v2
- uses: actions/setup-node@v1
- run: npm install -g firebase-tools
- name: Decrypt secret
run: ./decrypt_secret.sh environment.staging.ts
working-directory: ./.github/scripts
env:
LARGE_SECRET_PASSPHRASE: ${{ secrets.LARGE_SECRET_PASSPHRASE }}
- name: Move secret
run: mv $HOME/secrets/environment.staging.ts ./tuning-front/src/environments
- name: Build and Deploy to staging
run: ./build_and_deploy.sh staging
shell: bash
working-directory: ./enviroments/firesbase
env:
FIREBASE_TOKEN: ${{ secrets.SERVICE_ACCOUNT }}
needs: execute-e2eにより、execut-e2eが終わった後に実行されます。またe2eが失敗するとこのジョブは実行されません。
まとめと感想
Cypress × Firebase × Angular の組み合わせのE2EをGitHub Actionsで実行する方法を解説しました。改善点として、ファイルを暗号化してアップロードしている部分をできれば環境変数でなんとかでしたいなぁという感じです。もしいい方法あれば是非お願いします!
Cypress × Firebase × Angular の組み合わせのE2Eをlocalで実行する
AngularとFirebaseを使ったアプリケーションを作成し,CypressでE2Eを回したかったのですが,この構成のE2EをLocalで実行する方法を探すのに苦労したのでまとめようと思います.構成のイメージは以下の通りです.

今回はLocalでFirebaseを起動できるFirebase Emulatorを用いしました.
アプリケーションの用意
Angularアプリケーション
まずはAngularのアプリケーションを作成します.今回はFirestoreから取得したメッセージを表示するだけの単純なアプリケーションを作ります. 詳しくはこちらの公式サイトを見ていただきたいのですが以下のように雛形を作成します.
npm install -g @angular/cli // angular-cliのinstall ng new new-app //アプリケーションの雛形作成
app-component.htmlを以下のようにシンプルにします.
<p> メッセージ: 「ここにFirestoreから取得したメッセージを表示できるようにする」 </p>
試しにng serveでアプリケーションを起動してみてください
angular/fire
こちらを参考にangularのアプリケーションでfirebaseを操作する為にangular/fireをinstallします.
ng add @angular/fire
こちらでerrorが起きてしまう場合はnpmでinstallしてみてください.
npm install --save @angular/fire
次にfirebaseの設定を記述します.Angularではenviroment.prod.tsに本番用の設定を,envirment.tsに開発用の設定を記述します.(enviroment.local.tsなど開発でもさらに分けることも可能である)useEmulatorsはemulatorを使用するかで設定を書き換えないといけないので,その判断に利用するbooleanです.
enviroment.prod.tsには,実際にfirebaseのプロジェクトを作成し,以下の値を埋めて下さい.
export const environment = { production: true, useEmulators: false, firebase: { apiKey: '<your-key>', authDomain: '<your-project-authdomain>', databaseURL: '<your-database-URL>', projectId: '<your-project-id>', storageBucket: '<your-storage-bucket>', messagingSenderId: '<your-messaging-sender-id>', appId: '<your-app-id>', measurementId: '<your-measurement-id>' } };
今回はlocalでfirebase emulatorを使うので,envirment.tsには基本的にダミーの値を入れて頂いて大丈夫ですが,appIdだけは実際のものを使った方が良いです.後でemulatorつなげるときここをダミーにするとうまく繋がりませんでした.
export const environment = { production: false, useEmulators: true, firebase: { apiKey: 'api-key', authDomain: 'domain', databaseURL: 'database-url', projectId: 'new-app', storageBucket: 'storage-bucket', messagingSenderId: 'messaging-sender-id', appId: 'app-id', measurementId: 'measurement-id' } };
そしてapp.module.tsは以下のようになります
import { BrowserModule } from '@angular/platform-browser'; import { NgModule } from '@angular/core'; import { AppComponent } from './app.component'; import { AngularFireModule } from '@angular/fire'; import { AngularFirestoreModule } from '@angular/fire/firestore'; import { environment } from 'src/environments/environment'; import { SETTINGS as FIRESTORE_SETTINGS } from '@angular/fire/firestore'; import { USE_EMULATOR as USE_FIRESTORE_EMULATOR } from '@angular/fire/firestore'; @NgModule({ declarations: [ AppComponent, ], imports: [ BrowserModule, AngularFireModule.initializeApp(environment.firebase), AngularFirestoreModule ], // userEmulatorsのときlocalhostに向ける providers: [ { provide: USE_FIRESTORE_EMULATOR, useValue: environment.useEmulators ? ['localhost', 8080] : undefined }, ], bootstrap: [AppComponent] }) export class AppModule { }
この設定の上書きの仕方はどのバージョンのfirebaseを使っているかで変わるので詳しくはドキュメントを確認して下さい.
次に実際にFirestoreに値を取りに行く処理を実装します.
import { Injectable } from "@angular/core"; import { AngularFirestore } from "@angular/fire/firestore"; import { Observable } from "rxjs"; export interface Message { content: string; } @Injectable({ providedIn: 'root' }) export class FirebaseService { constructor(private firestore: AngularFirestore) { } getValueChanges(): Observable<Message[]> { return this.firestore.collection<Message>('messages').valueChanges(); } }
@Injectable({ providedIn: 'root' })でDIコンテナの管理下にこのクラスを置くことができます.
また今回はcontentとい文字列を持つmessagesというコレクションを用意することにします.
そしれこれをhtml上で表示できるようにapp.component.tsとapp.componetn.htmlを以下のように書き換えます.
import { OnInit } from '@angular/core';
import { Component } from '@angular/core';
import { Observable } from 'rxjs';
import { map } from 'rxjs/operators';
import { FirebaseService } from './firebase-service';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.scss']
})
export class AppComponent implements OnInit {
title = 'new-app';
message: Observable<string>;
constructor(private firebaseService: FirebaseService) { }
ngOnInit(): void {
this.message = this.firebaseService.getValueChanges().pipe(
map(value => value[0].content)
)
}
}
<p>
メッセージ: 「{{message | async}}」
</p>
| asyncはasync pipeというのですが,こうすることで非同期で値が取れたタイミングで値を表示してくれますし,obseableのunsubscribe をcomponentが破棄されるタイミングで勝手に呼んでくれます.
http-server
Angularのアプリケーションはng serveでも起動できるのですが,実際の本番環境ではビルド後のアプリケーションをサーバで起動すると思うので,その状態に近づける為ここではhttp-serverを使ってアプリを起動します.http-serverは以下のようにinstallします.
npm install -g http-server
installできたら
ng build npx http-server dist/new-app -p 4200
でアプリを起動することができます.
E2Eの用意
続いてこのメーセージが表示されることをE2Eテストを書いて確かめようと思います.
Cypress
まずはe2eのプロジェクトを作り,そこにCypressをインストールします.参考にしたサイトはこちらです
mkdir e2e
cd e2e
npm init -y //現在のディレクトリをnpmの管理下にする
npm install cypress typescript //cypressのインストール
npx tsc --init --types cypress --lib dom,es6 //tsconfig.jsonを作成
echo {} > cypress.json
以上のコマンドを実行したらpacage.jsonに以下のscriptを足してください.
"local:open": "cypress open",
"local:run": "cypress run"
そして以下のコマンドを実行するとCypressが起動し,cypressというディレクトリが作成されます.
npm run local:open
cypress/integrationとcypress/fixtureディレクトリは削除して頂いて大丈夫です.
Cypressはcypress/integration以下にテストを配置する仕様になっています.そこにディレクトリを作ってテストを分けることもできます.
以下のようなmessage.tsを作成します.
describe('ホーム画面 ', () => {
it('メッセージを見ることができる', () => {
cy.visit('http://localhost:4200/');
cy.contains('こんにちは').should('be.visible') // firestoreに「こんにちは」という値を入れてテストをする予定
})
})
アプリケーションをng serveで起動してテストを実行してみましょう.
以下の画面でファイル名を押すと実行できます.

firebase-emulatorの起動
次にfirebase-emulatorを実行できるようにしましょう. firebase cliをinstallします.
npm i -g firebase-tools
そしてfirebase用の初期化処理を以下で実行します.
firebase init
基本的に案内にそって進んで行くだけです.このときfirebaseのアカウントとプロジェクトが必要となるので,テスト対象のプロジェクトを選択してください.また今回はfirestoreしか使わないのでそこにチェックを入れてinstallしました.
次にfirebaseのfirestoreと管理画面を開くポート番号の設定をfirebase.jsonを作成し,記述します.
{
"emulators": {
"firestore": {
"port": 8080
},
"ui": {
"enabled": true,
"port": 4000
}
}
}
package.jsonのscriptに下記コマンドを足してください.
"emulators": "firebase emulators:start"
ここまでくれば下記コマンドを実行するとfirebase emulatorが起動します.
npm run emulators
コンソールログにfirestoreとuiのエンドポイントが表示されていると思います.uiのエンドポイントを開くと以下のような画面が表示されると思います.

firebase emulatorはこれを使ってfirestoreのデータを修正したり,authを使っている場合はユーザを作成したりと色々なことができます.
試しにここに値を埋めてみましょう.

こうするとさっき作成したテストが通ると思います. 今ここでは手動で値を入れましたが次はそれをテストの実行前に自動で投入できるようにしましょう.
Custom CommandsのTypescript化
cypress-firebaseというfirebaseのラッパーライブラリをinstallするのですが,その前にこのcypress-firebaseをtypescriptで使用する為の準備をします.普通にテストをtypescriptで書くことはできるのですが,他のライブラリや自分で作成したCustom Commands(cy.~で呼び出すコマンド)を使うときは少し変更が必要です.参考にさせて頂いたサイトはこちらです.
以下の依存関係をインストールします.
npm install --save-dev @babel/core @babel/preset-env babel-loader webpack npm install --save-dev @cypress/webpack-preprocessor npm install --save-dev @bahmutov/add-typescript-to-cypress
これを実行するとplungins以下にcy-ts-preprocessor.jsが生成され,またindex.jsが書き換わります.
次にcypress.jsonに以下のように記述します.
{
"supportFile": "cypress/support/index.ts"
}
そしてsupportFile/command.jsとsupportFile/index.jsをそれぞれsupportFile/command.tsとsupportFile/index.tsに変更します.
次にsupportFile/command.tsにexport {}を記述しモジュール化します.
これで準備はOKです.
私もここらへん完全に理解はできていないのですが,cypress.jsonに "supportFile": "cypress/support/index.ts"を記述したことにより,supportFile/index.tsが読み込まれるようになり,supportFile/index.tsからsupportFile/command.tsが読み込まれるようになってCustom Commandsが使えるようになります.そして@bahmutov/add-typescript-to-cypress が
supportFile/index.jsに
on('file:preprocessor', cypressTypeScriptPreprocessor)という記述や,supportFile/cy-ts-preprocessor.jsを生成し,tsファイルをトランスパイルしれくれる設定を色々やってくれるっぽいです.(参考)
cypress-firebase
いよいよcypress-firebaseをinstallします.
npm i --save-dev cypress-firebase firebase-admin
cypress-firebaseの公式のGitHubはこちらです. また環境変数で設定を切り替える為にcross-envをinstallします.
npm i --save-dev cross-env
support/command.tsに以下のように記述します.
import firebase from "firebase/app"; import "firebase/auth"; import "firebase/database"; import "firebase/firestore"; import { attachCustomCommands } from "cypress-firebase"; // 自分でCustom Commandsの書かなけらばここは必要はない declare global { namespace Cypress { interface Chainable<Subject> { } } } // angularアプリケーションのenviroment.tsと同じものでOK const fbConfig = { apiKey: "dummy-key", authDomain: "authDomain", projectId: "new-app-da206", storageBucket: "storageBucket", messagingSenderId: "dummyId", appId: "dummyId", measurementId: "dummyId" }; firebase.initializeApp(fbConfig); // Firebase Emulator用の設定 const firestoreEmulatorHost = Cypress.env("FIRESTORE_EMULATOR_HOST"); if (firestoreEmulatorHost) { // Emulatorを使用する際は設定を上書きする firebase.firestore().settings({ host: firestoreEmulatorHost, ssl: false, }); } attachCustomCommands({ Cypress, cy, firebase }); export { }
index.jsを以下のように変更する
const cypressTypeScriptPreprocessor = require('./cy-ts-preprocessor') const admin = require("firebase-admin"); const cypressFirebasePlugin = require("cypress-firebase").plugin module.exports = (on, config) => { on('file:preprocessor', cypressTypeScriptPreprocessor) const extendedConfig = cypressFirebasePlugin(on, config, admin); // Custom Commandsを足すときはここに追加していく return extendedConfig; }
データの初期化
次にテスト用のデータの初期化を実装していきます.
初期化の流れとしては
1. firestoreの messagesのデータを全て削除
2. firestoreの messagesにテスト用のデータを追加
という感じです.これをe2eが始まる一番はじめに1度実行します.途中でデータを書き換えると,副作用を持ってしまい並列化したときにテストが不安定になってしまうので一番はじめにデータをセットしてしまいます. またテスト用のデータはあるディレクトリに追加しておいてそれが自動的に追加されるようにします.
1,2を行う関数はsupport/setup.tsに記述することとします.
まずはmessagesのデータを全て削除するコードです.
export const clearMessagesData = () => { console.log('Clear messages data...') cy.callFirestore('delete', 'messages', { recursive: true }); }
cy.callFirestore()を呼び出すことでfirestoreを操作することができます.{ recursive: true }は再帰的に全て削除するという意味です.
次にファイルと読み込む実装をします.
実装のイメージは
1. ディレクトリ内のファイル名の一覧を取得する
2. そのファイル1つ1つを読み取り,firestoreに追加する
という風にします.
まず以下のようなファイルcypress/resource/message001.jsonに作成します.
{ "content": "こんにちは" }
1ではnodeのfs.readdirSyncを使ってフィル名の一覧を取得します.cypressではnodeの関数はtaskとしてのみ実行できます.なのでまずファイル名を取得するtaskをplugins/index.jsに追加します.
・ ・ const fs = require('fs'); module.exports = (on, config) => { ・ ・ on('task', { getFileNames(directoryPath) { return fs.readdirSync(directoryPath) } }); return extendedConfig; }
これを使ってfirestoreにデータを登録するコードは以下のようになります.
export const insertMessagesData = () => { console.log('Insert messages data...') cy.task('getFileNames', `${resoucePath}`) .then(fileNames => { (fileNames as string[]).forEach((f) => { cy.readFile<{ content: string }>(`${resoucePath}/${f}`) .then(message => { cy.callFirestore('set', `messages/${f.replace('.json', '')}`, message); }); }); }) }
ファイル名から.jsonを省いたidのmessageが登録されていきます.
これをcommands.tsに以下のような記述をすることでテストの最初に呼ぶようにします.
before(() => { clearMessagesData() insertMessagesData() })
実行
それではe2eテストを実行する為にpackage.jsonに以下のスクリプトを記述して下さい.
"local:open": "cross-env FIRESTORE_EMULATOR_HOST=\"localhost:$(cat firebase.json | jq .emulators.firestore.port)\" cypress open"
cross-envで環境変数FIRESTORE_EMULATOR_HOSTを定義しています.
またこれを実行すると以下のエラーが起きる場合があります.
> Unable to detect a Project Id in the current environment.
こういうときはスクリプトにGCLOUD_PROJECT=<projectId>という記述を足してください.cyress-firebaseでemulatorを使うときにはこうやってprojectIdを指定しないとうまく行かないようです.
cliでe2eをrunするスクリプトは以下のようになります.
"local:run": "cross-env FIRESTORE_EMULATOR_HOST=\"localhost:$(cat firebase.json | jq .emulators.firestore.port)\" GCLOUD_PROJECT=new-app-da206 cypress run"
感想
今回はCypress × Firebase × Angularという組み合わせでLocalでE2Eを実行する方法を解説しました.Firebase Emulator周りの設定が色々ややこしいとこがあるので皆様の参考になれば幸いです.こちらのコードは以下にpushしています. https://github.com/Yoshiaki-Harada/angular-firebase-cypress-for-blog-
アジャイルな見積もりと計画づくり
アジャイルな見積もりと計画づくりを読んだので,特に見積もりの方法についてまとめようと思います.
見積もりと計画づくりの目的
そもそも見積もりと計画づくりを行う目的は何なのでしょうか?それはこのソフトウェアがユーザに届ける価値の探究をする為です.その時点で最も価値が高い機能を届けるために,リソースを配分し,フィーチャのスコープを考えスケジュールを検討する.なので見積もりはこれに使える数値であればいいのです.正確にリリースの時期を予測する必要はなく,これらの意思決定を支えるレベルの見積もりを早く出すことが大切なのです.以下でお話させて頂くのはこの前提の元早く意思決定に使えるレベルの見積もりをどうやって出すかを記しています.
規模を見積もる
本書はアジャイル開発におけるユーザーストーリーの規模に対して見積りをすることを推奨しています.そして規模を見積もったあとに,ベロシティ(1イテレーションにおける消化したストーリーポイントの合計)を使うことで開発完了する期間を推定します.まさに距離と速度でかかる時間を導出するのと同じです.ここでいう規模とは必要な作業,開発内容の複雑さ,リスクを総合的に判断したものです.そしてこの規模をストーリーポイントと呼びます.

相対的に見積もる
ストーリーポイントは相対ポイントとしてつけます.ある基準のストーリーに対して,ある別のストーリーの規模は何倍かを考えてポイントをつけます.はじめの1つ目のストーリーは一番小さそうなストーリーを1ポイントにするか,真ん中ぐらいの規模のストーリーを想定するポイント幅の中央値にする方法があります.
なぜこのように見積もるのか?
1つ目の理由が長持ちするからです.あるストーリーが完了する作業時間というのは,使用する技術,経験によって変化します.例えばJavaの経験が浅いプログラマーがJavaを使って実装をすると時間がかかってしまいます.一方で慣れてくると同程度の規模のアプリケーションをもっと早く実装できるようになるでしょう.このように作業時間が変化するので,見積もりとしての賞味期限が短くなってしまうのです.

2つ目の理由が早く見積もれるからです.作業時間で見積もろうとすると具体的にどんな実装をするかを話してしまいがちです.相対的な規模で見積もることで,作業を想像することなく早く見積もることができます.見積もりは時間をかけてもどうせ不確実なもので,かつ意思決定を支えられればいいので時間をかけるのは勿体ないです.
3つ目の理由が属人化を防ぐことができるからです.作業時間で見積もるときはある人を想定して見積もることになります.なぜなら作業する人によって作業時間の見積もりが異なるからです.そうすると実際の作業もその人がやると決まってしまいます.規模の見積もりは人には関係ないのでこういったことを防ぐことができます.
4つ目の理由は相対的に見積もる方が正しく見積もれるからです.作業時間を絶対的に見積った場合は,作業時間と実際にかかった時間にかなりの差が現れたようです.しかしそのズレには一貫性があるようでした(アートオブアジャイルデベロップメントより).つまりある一定分ずれるといったことおきます.なので相対的に見積もるとうまくいくのです.相対的に見積もることの効果は普段の業務でも感じます.しっかりと規模に対して一貫性を持って相対的につけると,1週間あたりのポイントの消化分はほぼブレずに見積もれます.
見積もりの技法
この見積もりを行う際のコツについてもいくつか書かれたいので紹介します.
チームで見積もる
見積もりは,その作業を行う人が見積もるのが一番正確だと言われています.アジャイル開発においてはチームで仕事をするので,チームで見積もるのが一番正確なのです.また各人の思い込みを,他の人が指摘することで修正することができます.
プランニングポーカー
見積もりをする際のプロセスとしてプランニングポーカーという方法があります.大体以下のように行います. 1. チームで集まる 2. あるストーリーに対して各々が思うポイントをつけ,カードを出し合う 3. なぜそのポイントをつけたかを説明し,合意したポイントをそのストーリーにつける
プランニングポーカーで用いるカードの数字はフィボナッチ数列を扱うことが多いです.フィボナッチ数列は「0, 1, ,2 ,3 ,5 ...」という1つ前と2つ前を足した数でなる数列で,後ろに行くほど数字の振れ幅が大きくなります.実際の作業でも仕様の規模が大きくなればなるほど、作業工数の振り幅は大きくなっていきます.この性質とフィボナッチ数の性質がマッチしているのでフィボナッチ数を使っています. プランニングポーカーをやる際の注意でとしては,時間をかけすぎないことです.そもそも見積もりはどうやっても正確でにできないので時間をかけるとコスパに見合わなくなります.また僕の感覚的には,話し合いに時間がかかる時はストーリーのDoneの定義や,仕様上に認識のズレ,前提条件がうまく共有されていないことが多いです.まずはこちらの認識を合わせるかこのストーリーの見積もりを飛ばして,Doneの定義,仕様などを確認してからもう一度見積もり直すのがいいと思います.
ストーリーの分割
ストーリーを見積もる際にあまりに大きすぎるストーリーは見積もりの精度が低くなってしまいます.本書による人は10倍のものまでうまく見積もれるそうです.つまりストーリーポイントの最小単位が1ポイントならば,その10倍の規模の10ポイントのストーリーまではうまく見積もれるということです.なので大きすぎるなと思った際はストーリーを分割することを考えて見てください.また分割することで見積もりの精度というメリット以外にも,早くユーザーに価値が届く機能をリリースできたり,そのフィードバックを受けてのピボットがしやすくなります.以下の記事で分割については少しまとめているので良かったら参照してください. https://oboe-note.hatenablog.com/entry/2020/08/31/211001
ストーリーの結合
ストーリーを分割しすぎると逆に,精度が悪くなると言ったことも発生してしまいます.あるストーリーAをストーリー1〜4に分割して見積もるとします.それぞれのポイントが2~5ポイントだとすると,ストーリーAは最小で8ポイント,最大で20ポイントをつけることとなります.これらの数字はストーリーAとして考えた時おそらく違和感を感じてしまいます.なので分割しておかしいな?と思ったらまとめて,見積もり直してください.僕も仕事で見積もりをする上で,分割をしてポイントつけて合計を考えたときに,違和感を感じまとめて見積もり直して見たりします.

Angularの3種類のLoad方法について
最近Angularの勉強をやっているのでメモ半分でアウトプットしようと思います!今回はAngularのWebページのロード方法についての解説です.
通常のLoad
まずは通常のロードを使用した例をお見せしようと思います.このパターンは全てのページのモジュールを初回アクセス時に取得します.コードは以下にあげています. https://github.com/Yoshiaki-Harada/angular-lazy-load
今回はHOMEというページとSAMPLEというページを用意しました.SAMPLEというページにはchild1とchild2コンポーネントが埋め込まれています.HOMEからSAMPLEに飛べるように作成しています.
HOME
<h3> HOME </h3>
<br>
<ul>
<li><a [routerLink]="[ '/sample' ]">Sample</a></li>
</ul>
import { Component, OnInit } from '@angular/core'; @Component({ selector: 'app-home', templateUrl: './home.component.html', styleUrls: ['./home.component.scss'] }) export class HomeComponent implements OnInit { constructor() { } ngOnInit(): void { } }
SAMPLE
<h3>SAMPLE PAGE</h3>
<p>
This is Sample Page
</p>
<app-child1></app-child1>
<app-child2></app-child2>
CHILD
<p>child1 works!</p>
import { Component, OnInit } from '@angular/core'; @Component({ selector: 'app-child1', templateUrl: './child1.component.html', styleUrls: ['./child1.component.scss'] }) export class Child1Component implements OnInit { constructor() { } ngOnInit(): void { } }
child2はchild1とほぼ同じなので割愛します.
Routing
これらのHOMEページとSAMPLEページをRoutingに登録します.
import { NgModule } from '@angular/core'; import { Routes, RouterModule } from '@angular/router'; import { HomeComponent } from './home/home.component'; import { SampleComponent } from './sample/sample.component'; const routes: Routes = [ { path: '', component: HomeComponent }, { path: 'sample', component: SampleComponent }, ]; @NgModule({ imports: [RouterModule.forRoot(routes)], exports: [RouterModule] }) export class AppRoutingModule { }
プロジェクトを作成するときにrouteモジュールをimportするにyesと答えた場合app-routing.moduleというファイルは自動で生成されます.このroutesに自分が作成したコンポーネントを登録します.
またこのrouteに登録したページを表示するにはapp.component.htmlで以下のように<router-outlet></router-outlet>を登録する必要があります.
<router-outlet></router-outlet>
アクセス結果
アプリケーションをたて,接続してみるとmain.jsが22.5kBとなっています.

次にSampleページをクリックします.

特に追加でmoduleがロードされている様子はみられません.このように通常では全て最初にロードされます.
Lazy Load
次にそのページにアクセスされたタイミングはじめてロードするようにSampleページを作った場合を解説します.
Lazy Loadへの対応
lazy loadを実現するにはまずsample.module.tsを作成します.こちら先ほどのsample.component.tsと同階層に作成します.Child1Componet,Child2Componetもここで読み込むようにします.
import { NgModule } from '@angular/core'; import { CommonModule } from '@angular/common'; import { SampleRoutingModule } from './sample-routing.module'; import { SampleComponent } from './sample.component'; import { Child1Component } from './child1/child1.component'; import { Child2Component } from './child2/child2.component'; @NgModule({ declarations: [SampleComponent, Child1Component, Child2Component], imports: [ CommonModule, SampleRoutingModule ] }) export class SampleModule { }
次にsample-routing.moduleを作成します.
import { NgModule } from '@angular/core'; import { Routes, RouterModule } from '@angular/router'; import { SampleComponent } from './sample.component'; const routes: Routes = [{ path: '', component: SampleComponent }]; @NgModule({ imports: [RouterModule.forChild(routes)], exports: [RouterModule] }) export class SampleRoutingModule { }
次にapp-routing.moduleを以下のように変更します.
const routes: Routes = [ { path: '', component: HomeComponent }, { path: 'sample', loadChildren: () => import('./sample/sample.module').then(m => m.SampleModule) } ];
このloadChiledrenの部分がポイントで,pathのsampleにアクセスされてはじめてロードするということを表しています.
このコードは以下のコマンドを打つことで自動で生成することもできます.
ng g module sample --module app --route sample
アクセス結果
実際にアクセスしてみます.

main.jsのサイズが22.5kBより大分小さくなっていることが確認できます.このときSampleモジュールはまだロードされていないからです.
次にSampleページに飛んでみます.

sample-sample-module.jsがこのタイミングでロードされたことがわかります.このように遅延ロードを活用すると,最初のページに必要なモジュールを減らし,初めのページを表示する速度を早めることができます.
Pre Load
Pre loadとは初回のページはLazy Load通りに表示されるのですが,後でロードしてくるモジュールを,その後すぐにloadするというロード方法です.Lazy Loadでは訪れてはじめてloadされますが,Pre Loadは裏で先に準備しておくという感じです.
Pre Loadへの対応
app-routing.module.tsの
RouterModule.forRootにオプションとしてpreloadingStrategy:PreloadAllModulesを渡すだけPre Loadは実現できます.preloadingStrategyには他にもQuicklinkStrategyなどがあるそうです.
const routes: Routes = [ { path: '', component: HomeComponent }, { path: 'sample', loadChildren: () => import('./sample/sample.module').then(m => m.SampleModule) } ]; @NgModule({ imports: [RouterModule.forRoot(routes, { preloadingStrategy: PreloadAllModules })], exports: [RouterModule] }) export class AppRoutingModule { }
アクセス結果

このようにmain.jsがロードされた後でsample-sample-module.jsがロードされていることがわかります.
裏で初回ページは軽くしたいが,裏でロードしておいてして欲しい!って時にはこのPre Loadを使うのがいいと思います.
まとめ
Angularの3つのロード方法について解説しました.angular cliを使えば簡単にLazy Loadを使ったmoduleを作成できるので複数のページがあるアプリケーションを作りたい方はぜひ使うべきだなと感じました!!
Angularのライフサイクルについて
最近Angularについて勉強しているのでそこでの学びをアウトプットしようと思います. Angularのコンポーネントには,Angularがコンポーネントクラスをインスタンス化して,コンポーネントビューとその子ビューをレンダリングする時に開始するライフサイクルがあります.そして,別のページに遷移するなどを行うとライフサイクルが終了します. 今回はそのライフサイクルに合わせてフックされるライフサイクルフックメソッドを使ってAngulrarのライフサイクルについて説明します. Angularのライフサイクルフックメソッドは以下のような順番で呼び出されます.

主なメソッドについて説明します. - ngOnChanges - 入力プロパティを設定またはリセット,変更する度に呼び出される. - ngOnInit - Angularが入力プロパティを設定したあと,最初にコンポーネントを初期化するタイミングで呼び出される - ngDoCheck - コンポーネントの状態が変わる度に実行される.(Change DetectionというAngularの状態管理の仕組みが実行される度にこのメソッドがフックされる) - ngOnDestroy - コンポーネントが破棄されるタイミングで呼び出される.つまりDom上から削除されるとき.
コンポーネントの例
実際に呼び出されていることを確認するために,以下のような親と子コンポーネントを作成しました.以下に作成したアプリケーションのリンクを貼っておきます. https://github.com/Yoshiaki-Harada/angular-lifecycle
親コンポーネント
import { Component, DoCheck, OnChanges, OnDestroy, OnInit, SimpleChanges } from '@angular/core'; @Component({ selector: 'app-parent', templateUrl: './parent.component.html', styleUrls: ['./parent.component.css'] }) export class ParentComponent implements OnInit, OnChanges, OnDestroy, DoCheck { message: string isChiled = true constructor() { console.log('[Parent] constructor') } ngOnInit(): void { console.log('[Parent] ngOnInit') } ngDoCheck(): void { console.log('[Parent] ngDoCheck') } ngOnChanges(changes: SimpleChanges): void { console.log('[Parent] ngOnChanges') } ngOnDestroy(): void { console.log('[Parent] ngOnDestroy') } toggleChildView() { this.isChiled = !this.isChiled } }
<h2>親コンポーネント</h2>
<label for="message">メッセージ:</label>
<input type="text" name="message" id="message" [(ngModel)]="message">
<br>
<button (click)="toggleChildView()" type="button">子コンポーネントの表示を切り替える</button>
<div class="child" *ngIf="isChiled">
<app-child [message]="message"></app-child>
</div>
子コンポーネント
@Component({
selector: 'app-child',
templateUrl: './child.component.html',
styleUrls: ['./child.component.css']
})
export class ChildComponent implements OnInit, OnChanges, DoCheck, OnDestroy {
@Input() message: string
constructor() {
console.log('[Child] constructor')
}
ngOnInit(): void {
console.log('[Child] ngOnInit')
}
ngDoCheck(): void {
console.log('[Child] ngDoCheck')
}
ngOnChanges(changes: SimpleChanges): void {
console.log('[Child] ngOnChanges')
}
ngOnDestroy(): void {
console.log('[Child] ngOnDestroy')
}
}
<h3>子コンポーネント</h3>
<p>親から受け取ったメッセージは: {{message}}</p>
実行
このプログラムを実行しアクセスしてみると以下のようなログが出力されます.

これを見て頂くと前述の図の通りの動作していることが確認できます. 注意する点としてはコンストラクタが一番初めに呼び出されている点です.Angularは様々な初期化処理をコンストラクタではなく,ngOnInitでやることが推奨されています.コンストラクタが呼び出された時点では,入力プロパティに値がバインドされていない状況であり,コンポーネントが完成されていないからです.これは子コンポーネントのngOnInitがconstructor→ngOnChanges→ngOnInitと呼び出されていることからもわかります. また親コンポーネントのngOnChangesが呼び出されていないことがわかります.これは親コンポーネントには入力プロパティがないからです.Angularは入力プロパティがなく,受け取るものがないコンポーネントのngOnChangesをスキップします.
コンポーネントの変更
次に値を入力してみます.するとログには以下のように出力されます.

親,子コンポーネントともにコンポーネントは既に作成されているのでngOnInitは呼び出されていません. コンポーネントが変化したことを検知して,親のngDoCheckが呼び出されていることがわかります.また入力プロパティが変更されたため,子のngOnChangesが呼び出されています. これらのメソッドは以下のように一文字ずつ呼び出されます.

値が入力する度に特別な何かを行いたい時は,ngDoCheckに実装をすればOKです.しかしこれらのフックメソッドは何度も呼び出されるため,気を付けて実装しないとアプリケーションが重たくなってしまいます.
コンポーネントの破棄
最後にコンポーネントの破棄時に実行されるngOnDestroyについて確認します.(今回はngIfというDomの追加や削除が可能な構造ディレクティブを使って子コンポーネントを破棄しています.)
子コンポーネントの表示を切り替えるを押すとコンポーネントが削除されます.
ログの出力から子のngOnDestroyが呼び出されていることがわかります. このngOnDestroyの用途の例はコンポーネントが破棄されるタイミングでsubscribeしているObserableをunsubscribeしたいときです.
子コンポーネントに1秒ごとに値を発生させるintervalをsubscribeしてみます.
ngOnInit(): void {
console.log('[Child] ngOnInit')
this.subscription = interval(1000).subscribe(value => {
console.log('[Chile] number:' + value)
this.number = value
})
}
ngOnDestroyでこれをunsubscriibeしないで,実行してみます.

number: 6と出力されたあたりで表示の切り替えを2回ほど押すと,number: 0が出力されてしまいました.そしてその後number: 7が出力されています.これはコンポーネントが破棄されても,subscribe状態が続いておりメモリリークが起きてしまっていることを表しています.またnumber: 0が出力し始めているのはまたコンポーネントが生成されたタイミングで新たにsubscribeしたからです.
これを防ぐには以下のようにngOnDestroyでunsubscribe呼び出せばOKです.
ngOnDestroy(): void {
console.log('[Child] ngOnDestroy')
this.subscription.unsubscribe()
}
まとめ
Angularのライフサイクルについて解説しました.あまり使わないメソッドもありますが,初期化と破棄のタイミングではやりたいことがあることが多いので気を付けて実装しないといけないなと感じました.
DDDの集約について
今回はDDDの集約という概念についてこちらの本を元に解説したいと思います.僕自身DDDを勉強をする中,集約がいまいちつかめず,実際のコードでどの単位で集約を作ればいいか迷うことが多かったので,この本を読むことで少し理解が進んだのでメモ的にアウトプットしておきます.
集約とは
まず集約の定義について見ていきます.この本では様々なソースの集約の定義を載せてくれています.いくつかを抜粋しますと IDDDによると 集約は、エンティティとバリューオブジェクトをクラスタ化するために慎重に作られた一貫性のある境界です. Wikipediaによると 集約はルートエンティティによって結合されたオブジェクトの集合体です.集約のルートは,外部オブジェクトがそのメンバーへの参照を保持することを禁止することで,集約内で行われる変更の一貫性を保証します.
僕は正直この定義を見た時に何となくわかるが,一貫性って具体的に何?,その境界ってどう考えるの?っと思いました.そこでこの本の例を用いて説明していきます.
実際の例
本書で想定するアプリケーションは,UserがWishを作成してサービス上に登録できるサービスです.このとき以下の2つのケースにおいてUserとWishの間に保つべき一貫性があり,集約としてまとめるべきか 否かを考えていきます. 1. UserがいないとWishを作成することができないケース 2. ケース1の条件に加え,1User3つまでしかWishを作成できないケース
一貫性について考える時,並列で処理を行ったときに一貫性が保たれるか,破られるかを考えるとわかりやすいです. ケース1の場合だとプロセス1とプロセス2が並列で走った場合に以下のようになります.

ケース1の場合いくら並列で動いても一貫性が破られることがありません.なので集約としてUserとWishをまとめる必要はありません.
ケース2の場合だとプロセス1とプロセス2が並列で走った場合に以下のようになります.

ケース2だと図のように,プロセス1のWishの作成がコミットされる前に,プロセス2でWishのカウントが走ってプロセス2側から見たWishのカウントが2となってしまい,Wishを作成する場合が発生します.この結果1Userが作成できるWishが3つまでという条件が破られてしまいました.よってこの2つは守るべき一貫性があるのでUserとWishは集約としてまとめるべきです.また1Userが持つWishの数はUserが知るべきなのでルートエンティティはUserになります.
まとめ
集約をどうするかっていつも悩んでいたのですが,並列処理しても一貫性が保たれるかという考え方は1つ良い指標になるなと感じました.実際のコードは以下に上げているのでよかったら見てください. GitHub - Yoshiaki-Harada/aggregate-example
pluralsightのScaling Agileの講座を受けてみた
今回はpluralsightのScaling Agile - Coachingを受けてみましたので全体の概要と特に参考になった部分について解説しようと思います.
概要
こちらの講座はScaled Agile Frameworkと言う大規模な企業(数千人単位ぐらい)にアジャイルの考え方を導入する際のフレームワークについて解説された講座です.どのような順番でアジャイルを広めて行くかやアジャイルプラクティスについて解説が行われていたり,アジャイルにあった予算の配分方法についても解説がありました. 僕が所属するチームは50人ぐらいの開発チームなので大規模にどう導入して行くかはすぐ試せるほどの参考にはならなかったのですが,個々のプラクティスの説明には参考になった部分がありました. 今回は僕が特に参考になったと思ったユーザーストーリーの分割方法,その優先度づけの方法について説明します.
ユーザーストーリーの分割方法
アジャイル開発は短期間でリリースを頻繁に行います.そのためにはプラグラムが顧客にもたらす価値を表すユーザーストリーを細かく分割する必要がありますので,ここではその分割方法について紹介します.
CRUDで分ける
これは情報の操作する機能を作成,閲覧,更新,削除でストーリー分ける方法です.例えば「ジムのユーザーは自分のプロフィールの管理ができる」と言ったストーリーは以下のように分割することができます. - ジムのユーザーは自分のプロフィールを作成できる
ジムのユーザーは自分のプロフィールを閲覧できる
ジムのユーザーは自分のプロフィールを更新できる
ジムのユーザーは自分のプロフィールを削除できる
ステップで分ける
ステップで分けるとはある操作がいくつかのステップから成る時にストーリーをそのステップで分けると言った方法です.例えば「ジムのユーザーはプライベートレーニングスペースを予約できる」というストーリーは以下のように分割できます. - ジムのユーザーはプライベートレーニングスペースを選択できる
ビジネスルールで分ける
ビジネスルールで分けるというのはある操作する時に複数のルールが存在するときそれぞれで別のストーリーに分けて考えるという方法です.例えば「ジムのユーザーはクレジットカードで支払いをすることができる」というストーリーは以下のように分割できます. - ジムのユーザーはクレジットカードで支払いをすることができる
ジムのユーザーは間違ったクレジット番号を入力すると警告される
ジムのユーザーはクレジットカードの限度額を超ている場合警告される
データのバリエーションで分ける
これはある情報を複数の形式や,複数の言語で見せたい時にそれぞれで分けると言った法う方です.例えべ「ジムのユーザーは母国語でアプリをみることができる」というストーリーは以下のように分割できます. - アプリを日本語で見ることができる
- アプリを英語で見ることができる
入力方法で分ける
これはあることをするための入力方法が複数考えられる時それぞれでストーリーを分けると言った方法です.例えば「ジムのユーザーは検索結果からかリストからエクササイズを選択できる」というストーリーの場合以下のように分割することができます. - ジムのユーザーは検索結果からエクササイズを選択できる
- ジムのユーザーはリストからエクササイズを選択できる
品質で分ける
これはある機能を作りたい時に,品質が低い状態ではあるがそれが達成できるストーリーと,品質は高いが困難で時間がかかりそうなストーリーを分けると言った方法である.例えば「ジムのユーザーはジムの進捗状況を確認することができる」というストーリーは以下の2つのストーリーとして分けることができます. - ジムのユーザーはジムの進捗状況を1日ごとに確認することができる
- ジムのユーザーはジムの進捗状況をリアルタイムで確認することができる
こうすることで本当はリアルタイムで見たいかもしれないが,難しいく時間がかかるのでまずは1日ごとで確認できるような機能をリリースするという選択をとることができます.またユーザーに価値を届けてみるとこれで十分という反応が返ってきてリアルタイムな機能を実装せずに済むかもしれません.
ストーリーの優先づけの方法: WSJF
以前アートオブアジャイルデベロップメントではストーリーの優先度を決める方法として計画ゲームを紹介しました.XPの計画ゲームではプロダクトオーナーに優先度を決めてもらう方式でしたが今回ご紹介する方法やプロダクトオーナーが複数の場合やステークホルダーが複数の場合,またストーリーのサイズの大きさも考慮して決める時に有効な方法であるWeighted Shortest Job First (WSJF)ついてご紹介します.
これはCost Of Delayというそのストーリの実装を遅らせることにより発生するコストをストーリーの大きさであるJob Sizeで割ってその値大きい順番に優先度が決まる方法です.
WSJF = Cost Of Delay/Job Size
このCost of Delayは以下の3つの要素の和となっています.
Cost of Delay = User business value + Time criticaly + Risk reduction/ Opportunity enablement value
- User business value
- ユーザーに対してどれだけの価値を届けられるか
Time criticaly
- 早くすることにどれだけ価値があるか
Risk reduction/ Opportunity enablement value
- 将来のリスクをどれだけ減らせるか / 別プロジェクトへ繋がって価値を生み出せそうか
これらの値はそれぞれある基準のストーリーに対する相対ポイントによって決まります.これらはプロダクトオーナーやステークホルダーが参加し,ある基準のストリートのUser business valueやTime criticalyのポイントを決めて,それに対する相対ポイントを出し合い,話あって決めていきます.ストーリーポイントを決めるプランニングポーカーが参考になります. User business value以外の2つはわかりにくいので少し説明します.Time criticalyはキャンペーンサイトの実装などが当てはまります.クリスマス用のキャンペーンサイトはクリスマスをすぎると意味がなくなるのでTime criticalyポイントが高くなります.Risk reductionとはセキュリティ対応などが当たります. Job Sizeはストーリーポイントや,複数のストーリーをまとめて考える場合はその合計を表します. 以下にテンプレートを載せておきます.https://www.scaledagileframework.com/wsjf/

ここで言うFeatureはストーリやその集まりのことを指しています.
Cost Of Delay/Job Sizeの高い順番を優先で実装することで常にその単位当たりの時間で最も価値の高い状態を維持できます.またCost Of Delayを複数の人でポイントを出し合って決めるのでより多くの人が決まった優先順位に納得することができます.
感想
今回は初めてpluralsightを受けて見たのですが,英語がわりかし早くて大変でした..笑 ただアートオブアジャイルデベロップメントにはないプラクティスが紹介されていたり,そもそもアジャイルではない組織にどう導入するかや大きな組織にどう対応するかが解説されており学びも多かったです.